Abstract
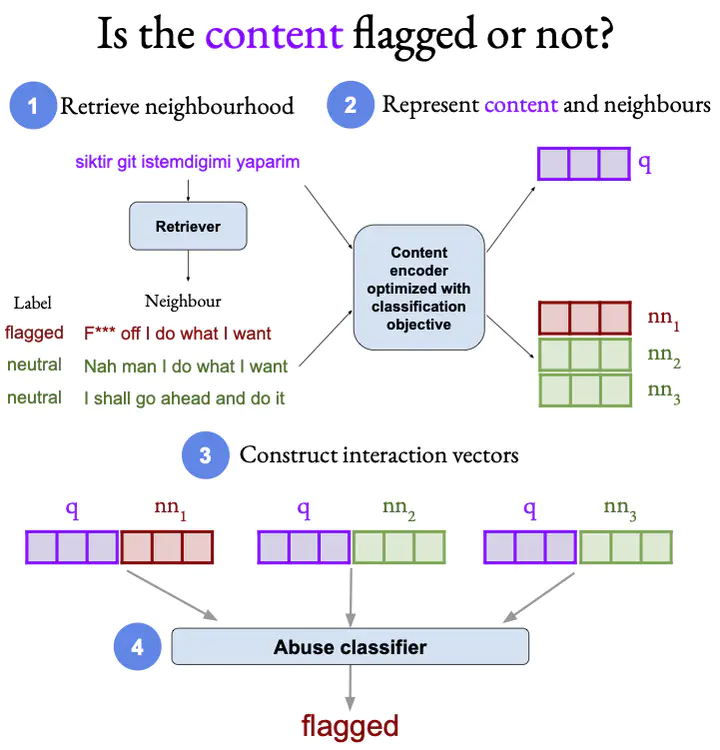
We propose a novel framework for cross-lingual content flagging with limited target-language data, which significantly outperforms prior work in terms of predictive performance. The framework is based on a nearest-neighbour architecture. It is a modern instantiation of the vanilla k-nearest neighbour model, as we use Transformer representations in all its components. Our framework can adapt to new source-language instances, without the need to be retrained from scratch. Unlike prior work on neighbourhood-based approaches, we encode the neighbourhood information based on query–neighbour interactions. We propose two encoding schemes and we show their effectiveness using both qualitative and quantitative analysis. Our evaluation results on eight languages from two different datasets for abusive language detection show sizable improvements of up to 9.5 F1 points absolute (for Italian) over strong baselines. On average, we achieve 3.6 absolute F1 points of improvement for the three languages in the Jigsaw Multilingual dataset and 2.14 points for the WUL dataset.
Momchil Hardalov
Applied Scientist
My research interests include natural langauge processing, few-shot, semi-supervised and multilingual learning. I have a strong software engineering background as a Software and Machine Learning Engineer.