Biography
I am an Applied Scientist in Natural Langauge Processing (NLP) at Amazon AWS AI Labs. My research interests include question answering, conversational agents, patterns-based few-shot learning, distant supervision, cross-lingual and cross-domain transfer. Before joining Amazon, I was a Research Scientist at Checkstep Research, where I worked on NLP for content moderation using few-shot learning, semi-supervised and multi-source fine-tuning of pre-trained language models. I did my Ph.D. at Sofia University “St. Kliment Ohridski” on dialog and question answering systems.
I have a strong software engineering background along with extensive experience in developing production systems. I previously held a position as a Machine Learning Engineer at ReceiptBank (now Dext) where I built NLP models for automatic field information extraction from unstructured payment documents. I was also a Machine Learning Engineer in an ad-tech company, Adcash OÜ, where I developed distributed and scalable models for ad recommendations. Prior to that, I created and maintained desktop and web applications while in the roles of a full-stack Software Engineer and Team Lead at Acstre.
For more details you can download my CV and see a list of my publications.
- Natural Language Processing
- Few-Shot Learning with Large Language Models
- Semi-Supervised Learning
- Multilingual Learning
- Stance Detection
- Abusive Language Detection
- Question Answering
- Conversational Agents
-
Ph.D. Candidate in Natural Language Processing, 2017-2023 (Expected)
Sofia University "St. Kliment Ohridski", Sofia, Bulgaria
-
MSc in Information Retrieval and Knowledge Discovery, 2014-2016
Sofia University "St. Kliment Ohridski"
-
BEng in Computer Systems and Technologies, 2010-2014
Technical University-Sofia
Recent News
- I joined Amazon AWS AI Labs as an Applied Scientist. I will be working on NLP for information extraction from conversational threads. Oct 2022.
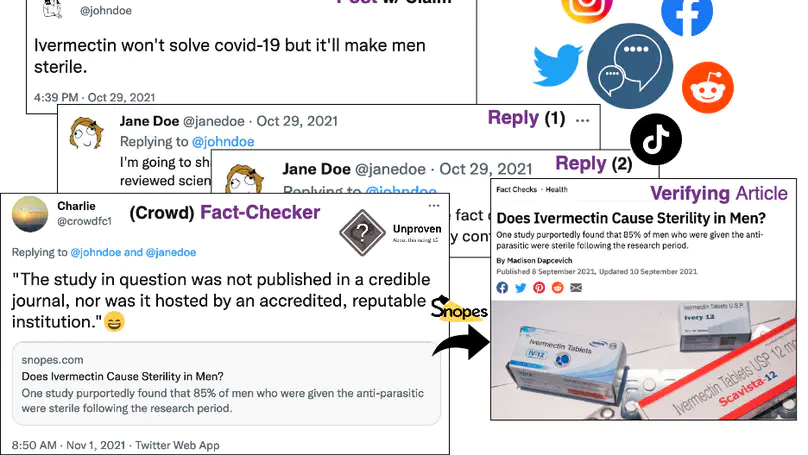
- Our long paper on CrowdChecked: Detecting Previously Fact-Checked Claims in Social Mediae was accepted to AACL-IJCNLP-22 (oral presentation). Oct 2022.
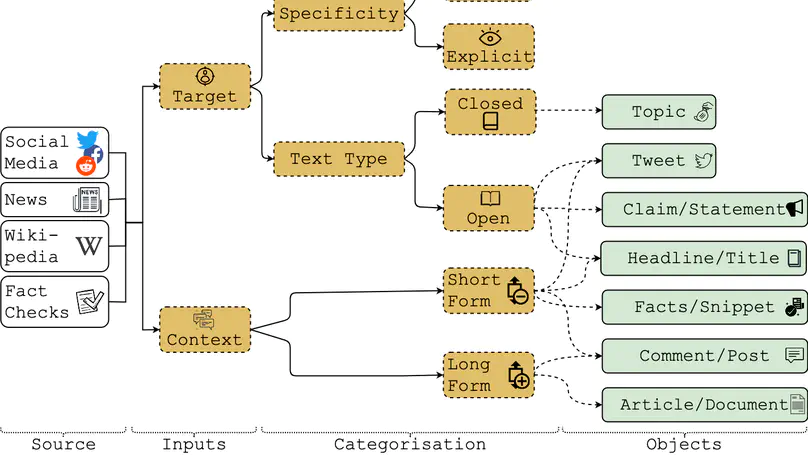
- Presented our survey on Stance Detection for Stance Detection for Mis- and Disinformation Identification at NAACL-HLT-22 in Seattle, USA. Jul 2022.
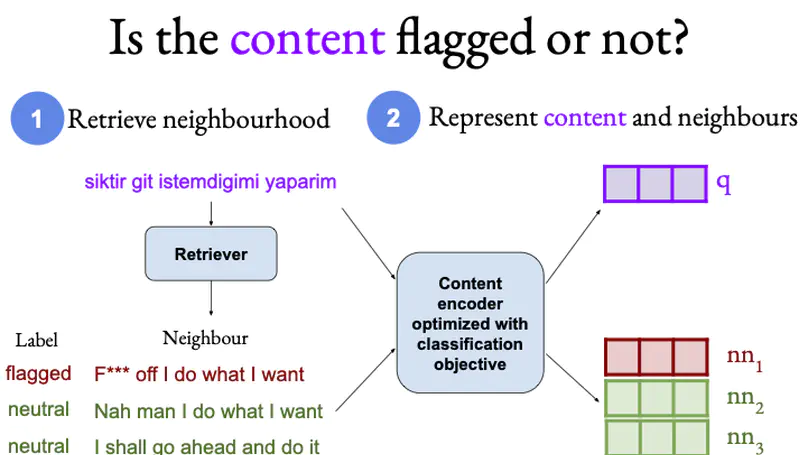
- Presented our TACL journal paper on A Neighbourhood Framework for Resource-Lean Content Flagging at ACL-22 in Dublin. May 2022.
- Our survey paper on Stance Detection for Stance Detection for Mis- and Disinformation Identification was accepted to Findings of NAACL-HLT-22. Apr 2022.
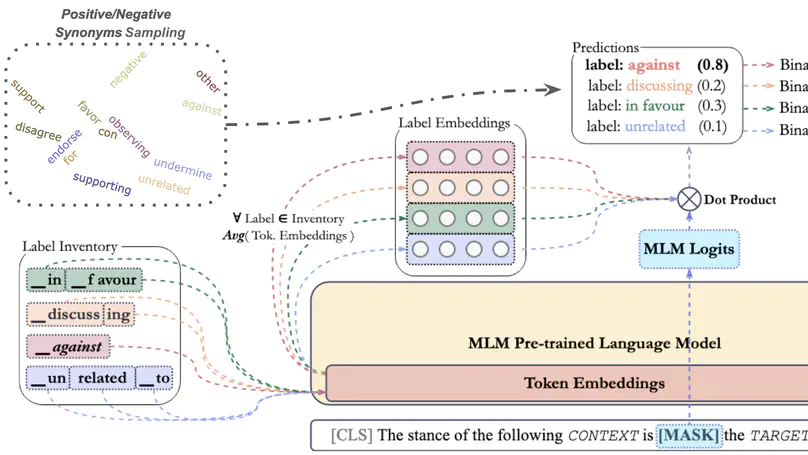
- Presented our work on Few-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training at AAAI-22 online. Feb 2022.
- Our paper Few-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training was accepted to AAAI-22 (oral presentation, overall acceptance rate of 15%). Dec 2021.
- Our work on A Neighbourhood Framework for Resource-Lean Content Flagging was accepted to appear in TACL. Dec 2021.
- A demo paper on Question Generation was accepted at ECIR-2022. The work is part of the master thesis of Kristiyan Vachev, whom I’m co-supervising. Nov 2021.
- Presented our work on Cross-Domain Stance Detection at EMNLP 2021 in Punta Cana, Dominican Republic. Nov 2021.
- Attended ACL 2021 online. Aug 2021.
- Our paper Cross-Domain Stance Detection was accepted to EMNLP 2021, Main Conference. Aug 2021.
- Team DIPS was ranked 1st at Task 2B (Detect Previously Fact-Checked Claims in Political Debates/Speeches) at the CLEF-2021 CheckThat! competition. The system is developed by a group of MSc students as part of our Text Mining course. May 2021.
- I officially joined Checkstep Research as a Research Scientist. I will be working on NLP for content moderation and stance detection. Nov 2020.
- Presented our work on EXAMS: Cross-Lingual QA at EMNLP 2020 online. Nov 2020.
Experience
Conducted research in natural language processing for content moderation and stance detection.
- Published 5 scientific papers, 4 are accepted to appear in top-tier venues.
- Developed, productionalized and delivered models to end clients in collaboration with the dev team.
- Curated machine learning models based on the specifics in the clients' policy definitions.
- Worked on few-shot and multi-domain learning for mono and cross-lingual stance detection.
- Researched semantic neighborhood models for cross-lingual abusive language detection.
Worked on automatic field information extraction from unstructured payment documents.
- Improved the extraction coverage and the overall accuracy of key fields (4%--10% depending on the field and the metric).
- Developed models for new (client requested) fields working closely with the Business team.
- Researched, prototyped, and productionalized machine learning models.
Developed distributed and scalable product serving ad recommendations.
- Increased the company's profit by 7% with a new ad serving (exploitation) model.
- Increased the ad diversity by 12% and the revenue by 5% with a new (exploration) model.
- Researched, prototyped, and productionalized machine learning models.
- Designed and executed experiments (A/B tests) for model optimizations.
- Worked closely with the Business team to design new features.
Designed, developed and maintained desktop and web applications. Led a small team of developers.
- Productionalized an unified user management and security system integrated into more than 20 company products spanning over 250 organizations.
- Built an event-based notification system with communication channels as plug-ins.
- Successfully migrated existing projects' legacy database management system to PostgreSQL.
- Delivered multiple software projects by leading 3-5 people project teams.
- Gathered technical specifications for new products/features from clients.